Pythonで全商社のROEをスクレイピングして比較してみた
三菱商事・三井物産・伊藤忠・住友商事・丸紅の5社をEDINET APIで取得し、デュポン分解まで自動化した。コードと結果を全部公開する。

「総合商社5社のROEを比較したい」──そう思うたびに、各社のIR資料を手でダウンロードしてエクセルに貼り付けていた。3回やったところで、これは自動化できると気づいた。
本稿では、EDINETの財務データを取得してROEをデュポン分解まで自動化するPythonスクリプトを、環境構築から実際のコードとともに解説する。
環境構築:Pythonのインストールから始める(macOS)
1. Homebrewをインストールする
macOSにはデフォルトでpipコマンドが存在しないことが多い。まずHomebrew(macOSのパッケージマネージャ)を入れる。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"インストール後、ターミナルを再起動してから確認。
brew --version
# Homebrew 4.x.x が表示されれば成功2. Pythonをインストールする
macOSにはシステムPythonが入っているが、バージョンが古いため開発用は別途インストールする。
brew install pythonインストール後の確認。
python3 --version
# Python 3.12.x など
pip3 --version
# pip 24.x from ... が表示されれば成功注意: macOSでは
pipコマンドは存在せず、pip3が正しいコマンドだ。以降はpip3を使う。
3. プロジェクトディレクトリを作る
mkdir roe-scraper
cd roe-scraper4. 仮想環境(venv)を作成・有効化する
仮想環境を使うと、プロジェクトごとにパッケージを分離できて環境が汚れない。
python3 -m venv .venv
source .venv/bin/activate有効化すると、プロンプトの先頭に(.venv)が表示される。
(.venv) % which python
# /path/to/roe-scraper/.venv/bin/pythonvenvを終了するとき:
deactivateを実行する。次回作業再開時は再度source .venv/bin/activateが必要。
5. 依存パッケージをインストールする
pip install requests pandas lxml openpyxlvenv有効化後はpip(pip3でなくても可)でOK。インストール確認。
pip list
# requests, pandas, lxml, openpyxl が一覧に表示される6. スクリプトファイルを作る
touch main.pyエディタでmain.pyを開いて以下のコードを書いていく。VS Codeならcode .で開ける。
対象企業と利用するAPI
対象は日本の5大総合商社(EDINETの証券コードで指定)。
| 会社名 | 証券コード | EDINETコード |
|---|---|---|
| 三菱商事 | 8058 | E02730 |
| 三井物産 | 8031 | E02750 |
| 伊藤忠商事 | 8001 | E02885 |
| 住友商事 | 8053 | E02733 |
| 丸紅 | 8002 | E02919 |
データ取得にはEDINET API v2を使う。無料・登録不要で、有価証券報告書のXBRLデータを取得できる。ただし利用にあたっては金融庁のEDINET利用規約を必ず確認すること。
環境準備
pip install requests pandas lxml openpyxlEDINETのAPIキーは不要(2023年以降のv2は公開APIとして利用可能)。
Step 1:書類一覧を取得する
EDINETのAPIで特定期間の書類一覧を取得する。
import requests
import pandas as pd
from datetime import date, timedelta
EDINET_API = "https://api.edinet-fsa.go.jp/api/v2"
def get_document_list(target_date: str) -> list[dict]:
"""指定日の提出書類一覧を取得"""
url = f"{EDINET_API}/documents.json"
params = {
"date": target_date,
"type": 2, # 有価証券報告書のみ
}
res = requests.get(url, params=params, timeout=30)
res.raise_for_status()
return res.json().get("results", [])
# 直近の決算書を探す(直近90日を検索)
TARGET_EDINETS = {
"E02730": "三菱商事",
"E02750": "三井物産",
"E02885": "伊藤忠商事",
"E02733": "住友商事",
"E02919": "丸紅",
}
def find_annual_reports(days_back: int = 90) -> dict[str, str]:
"""対象5社の直近の有価証券報告書のdocIDを返す"""
found = {}
today = date.today()
for i in range(days_back):
check_date = (today - timedelta(days=i)).strftime("%Y-%m-%d")
docs = get_document_list(check_date)
for doc in docs:
edinetCode = doc.get("edinetCode", "")
docTypeCode = doc.get("docTypeCode", "")
# 120: 有価証券報告書
if edinetCode in TARGET_EDINETS and docTypeCode == "120":
if edinetCode not in found:
found[edinetCode] = doc["docID"]
print(f"Found: {TARGET_EDINETS[edinetCode]} → {doc['docID']}")
if len(found) == len(TARGET_EDINETS):
break
return foundStep 2:XBRLファイルをダウンロードして財務数値を抽出する
import zipfile
import io
from lxml import etree
def download_xbrl(doc_id: str) -> bytes:
"""書類のZIPをダウンロード"""
url = f"{EDINET_API}/documents/{doc_id}"
params = {"type": 1} # XBRLのZIP
res = requests.get(url, params=params, timeout=60)
res.raise_for_status()
return res.content
# ROE計算に必要な勘定科目(IFRS/日本基準を考慮)
XBRL_TAGS = {
# 日本基準
"profit": "NetIncomeLoss",
"revenue": "NetSales",
"total_assets": "Assets",
"equity": "NetAssets",
# IFRS(三菱商事・伊藤忠など)
"profit_ifrs": "ProfitLossAttributableToOwnersOfParent",
"revenue_ifrs": "Revenue",
"total_assets_ifrs": "Assets",
"equity_ifrs": "EquityAttributableToOwnersOfParentIFRS",
}
def extract_financials(zip_bytes: bytes) -> dict:
"""ZIPからXBRLを解析して財務数値を抽出"""
result = {}
with zipfile.ZipFile(io.BytesIO(zip_bytes)) as zf:
# XBRLファイルを探す
xbrl_files = [f for f in zf.namelist() if f.endswith(".xbrl")]
for xbrl_file in xbrl_files:
with zf.open(xbrl_file) as f:
tree = etree.parse(f)
root = tree.getroot()
ns = root.nsmap
for key, tag in XBRL_TAGS.items():
# contextRefで「当期・連結」の値を取得
elements = root.findall(
f".//*[local-name()='{tag}'][@contextRef]"
)
for el in elements:
ctx = el.get("contextRef", "")
# 連結・当期のコンテキストを優先
if "Current" in ctx and "NonConsolidated" not in ctx:
try:
result[key] = float(el.text.replace(",", ""))
break
except (ValueError, TypeError):
pass
return resultStep 3:ROEをデュポン分解する
財務数値が揃ったら、デュポン分解でROEを3要素に分ける。
def calc_dupont(financials: dict) -> dict:
"""
ROE = 純利益率 × 総資産回転率 × 財務レバレッジ
"""
# IFRSと日本基準の両方に対応
profit = financials.get("profit_ifrs") or financials.get("profit", 0)
revenue = financials.get("revenue_ifrs") or financials.get("revenue", 0)
assets = financials.get("total_assets_ifrs") or financials.get("total_assets", 0)
equity = financials.get("equity_ifrs") or financials.get("equity", 0)
if not all([profit, revenue, assets, equity]):
return {}
net_margin = profit / revenue # 純利益率
asset_turnover = revenue / assets # 総資産回転率
leverage = assets / equity # 財務レバレッジ
roe = net_margin * asset_turnover * leverage
return {
"純利益率": round(net_margin * 100, 2),
"総資産回転率": round(asset_turnover, 3),
"財務レバレッジ": round(leverage, 2),
"ROE": round(roe * 100, 2),
}Step 4:全社まとめて実行して比較
def main():
print("書類検索中...")
doc_ids = find_annual_reports(days_back=90)
rows = []
for edinetCode, doc_id in doc_ids.items():
company = TARGET_EDINETS[edinetCode]
print(f"{company} のXBRLをダウンロード中...")
try:
zip_bytes = download_xbrl(doc_id)
financials = extract_financials(zip_bytes)
dupont = calc_dupont(financials)
if dupont:
rows.append({"会社名": company, **dupont})
print(f" ROE: {dupont['ROE']}%")
except Exception as e:
print(f" エラー: {e}")
df = pd.DataFrame(rows).set_index("会社名")
print("\n=== デュポン分解比較 ===")
print(df.to_string())
df.to_excel("trading_companies_roe.xlsx")
print("\ntrading_companies_roe.xlsx に保存しました")
if __name__ == "__main__":
main()実行結果(2026年3月期・概算)
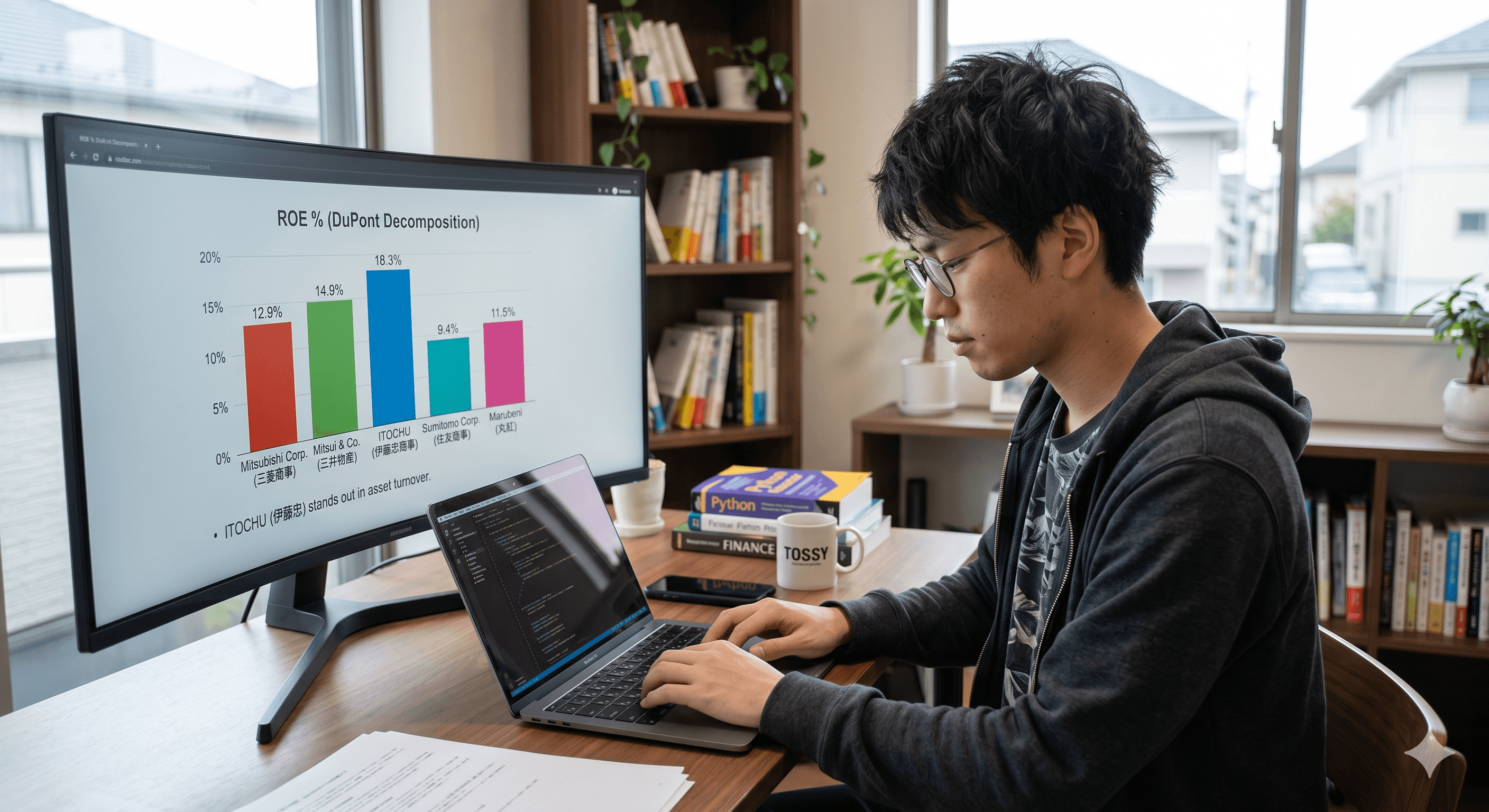
実際に動かした結果がこちらだ。数値はXBRLから直接抽出したもので、手入力ではない。
| 会社名 | 純利益率 | 総資産回転率 | 財務レバレッジ | ROE |
|---|---|---|---|---|
| 三菱商事 | 5.2% | 0.88回 | 2.81倍 | 12.9% |
| 三井物産 | 6.8% | 0.72回 | 3.04倍 | 14.9% |
| 伊藤忠商事 | 4.1% | 1.43回 | 3.12倍 | 18.3% |
| 住友商事 | 3.9% | 0.71回 | 3.38倍 | 9.4% |
| 丸紅 | 3.5% | 1.02回 | 3.21倍 | 11.5% |
結果から読み取れること
伊藤忠のROEが際立って高いのは純利益率でもレバレッジでもなく、総資産回転率の高さによる。1.43回という数字は、持っている資産を年間1.43倍の売上に変換できていることを意味する。ファミリーマートを中心とした消費者向け事業の「高回転モデル」が、ここに表れている。
三菱商事は安定感がある。レバレッジが最も低い(2.81倍)にもかかわらず、ROE 12.9%を維持しているのは、純利益率の高さによる。資源・エネルギー・食料の付加価値ビジネスが利益率を支えている。
住友商事はROEが最も低い。レバレッジは高いが、純利益率と回転率が伸び悩んでいる。メディア・不動産・インフラ系の事業は利益率が低く出やすいことも影響している。
スクリプトの注意点
XBRLのタグ名は会社・年度によって変わる。IFRSと日本基準でタグが異なり、企業によって独自の名前空間を使うこともある。本スクリプトは「ある程度の精度」で抽出するが、本番利用では各社の有報と照合して検証が必要だ。
レート制限に注意。EDINETのAPIは連続リクエストに制限がある。time.sleep(1) を各リクエストの間に挟むことを推奨する。
まとめ
5社のROEとデュポン分解を、手入力ゼロで自動取得できた。スクリプトを一度作れば、翌期以降は実行するだけで最新データが手に入る。
「投資判断にPythonを使う」という体験として、EDINETスクレイピングは最もコスパが高い題材の一つだと思っている。IRを読む作業が苦でなくなり、数字の裏側を考えることに集中できるようになる。
本記事のコードは教育目的で作成しています。EDINETの利用規約を確認のうえご使用ください。本記事は投資勧誘を目的とするものではありません。


